grep and sed only the numbers from a text file's line
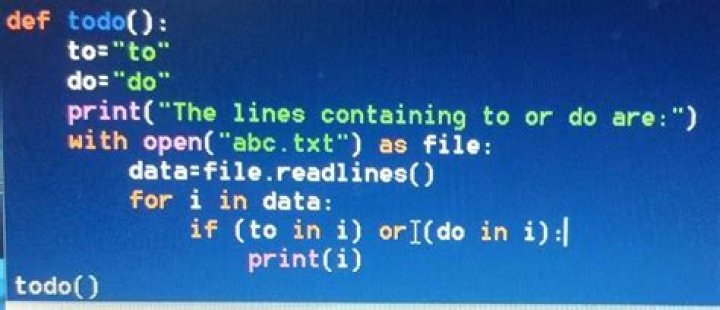
I'd like to extract only a number from a text file. It is like:
corner_lat: 49.0425000 decimal degreesI am using the following expression :
grep corner_lat EQA.dem_par | sed "s,[^0-9]*,,"but this gives back also the "decimal degrees" How can modify this to get only the number?
2 Answers
You have to use g (global substitution) to replace all occurrences of pattern you are looking for:
grep corner_lat EQA.dem_par | sed "s/[^0-9.]*//g"or as you wrote it:
grep corner_lat EQA.dem_par | sed "s,[^0-9.]*,,g"Don't forget to add . in character class otherwise it will be removed too.
Your command only removes first occurrence of the pattern which is:
corner_lat: And leaving:
49.0425000 decimal degreesIf the format of all lines in the file is the same, you can use awk or cut instead of sed to extract only the second colum.
As an example:
grep corner_lat EQA.dem_par | awk '{print $2}'

