CUDA vs tensor cores in high FLOPs settings
RTX2080S trains x1.6 faster than GTX1070 for small models. For a model with 1+ TFLOPS, however, it trains x6 faster - and I can't understand why.
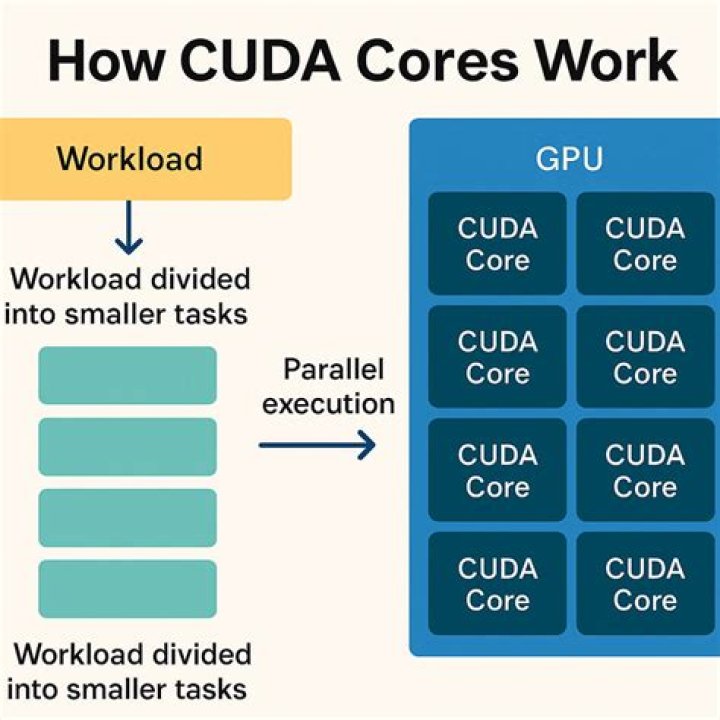
The RTX has only x1.6 as many cores as the GTX (3072 vs 1920) and similar clock speeds, but with RTX having 384 tensor cores. Benchmark comparison doesn't show any figure at 500%+ however.
Is this expected, and if so, how's it explained? Do tensor cores just have that much greater "FLOP capacity"?
Setting: automatic mixed precision, PyTorch; same software (OS, Anaconda environments), models, datasets; RAM and VRAM not saturated. "Training" = applying bunch of math on input arrays, "bigger model" = more math on more data (at the same time, i.e. in parallel).
2 Reset to default